104万行の壁を越える!Power QueryとPower Pivotの研究
Excel 2019に付いているPower QueryとPower Pivotの研究
ほぼ自分用メモであるが、日本語の分かりやすい記事が少ないので、初心者の参考になれば幸い。
Power Queryは、どんな時に使うかといえば、
・SQL Serverなど外部のデータベースにデータが入っているのをExcelに読み込んでBI的なことをしたい
・104万行を超えるビッグデータを分析したい
・Excel基本機能だけだとちょっと面倒な加工をしたい(これはおまけ程度)
という3つの使い方が考えられる。これ以外はExcel関数でできるので無理に使う必要もないと思う。
私の用途は主に104万行オーバーの分析。金融の時系列データや自然言語でコーパス(辞書)を作りたいなどの場合、104万行を超えることは多い。
実際、Power QueryとPower Pivotの位置づけとして、104万行の壁を越えるために提供されている感はあり。
Excel内にSQLエンジンを提供して、104万行を超えるデータはSQLにすべて放り込んで、そこから抽出した結果「だけ」をExcel上に104万行以内で表示しろ。という設計思想になっている気がする。
なお、使ったことはないがPower BIもPower Query+Power Pivotのようなソフトである(むしろPower BI用に作ったシステムがExcelのおまけ機能として転用されている?)
Power Queryの基本
Power Query起動
ここからPower Queryエディターの起動
基本的なデータのインポート
Power Queryエディターが起動したらクエリの上で右クリックしてCSVファイルなどを選ぶ
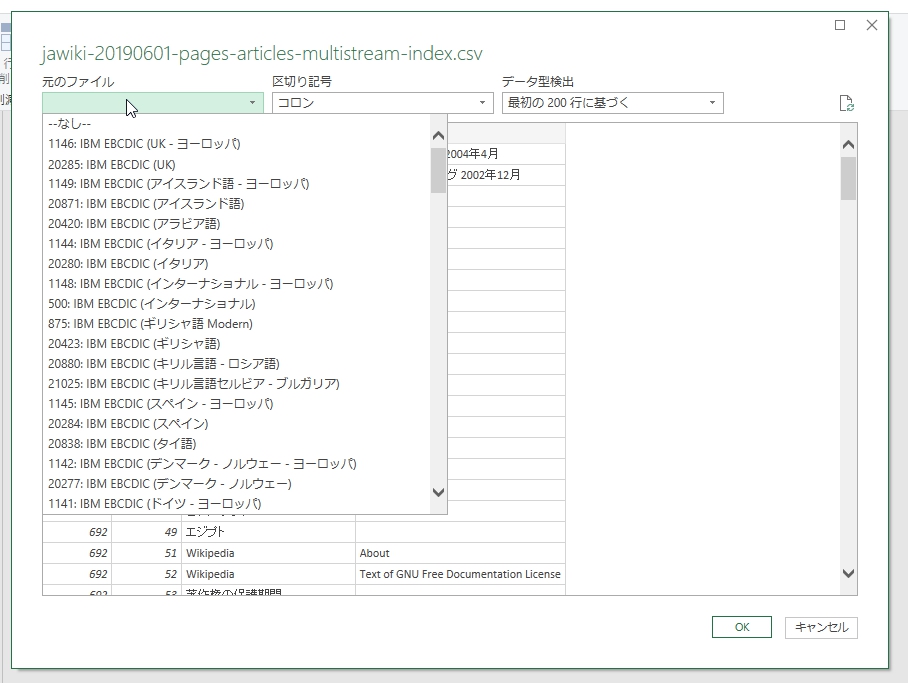
文字コードやデリミタ(区切り文字)を設定しつつデータを読み込む
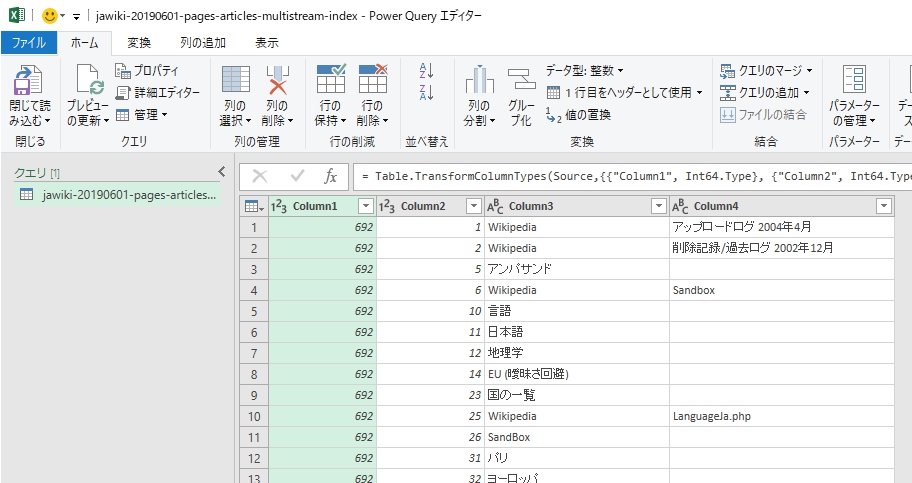
Wikipediaの単語データ200万件くらいが読み込まれた。この時点ではクエリからCSVを参照しているだけでxlsxファイルにテーブルのデータは保持されない
同じ書式のExcelファイルを結合
形式(フィールド)がまったく同じExcelファイルがたくさんある場合、それを結合したいことはよくある。
たとえば、月次の集計データが20年分、240ファイルのxlsxに分割されていて、これをひとまとめにしたい時など。
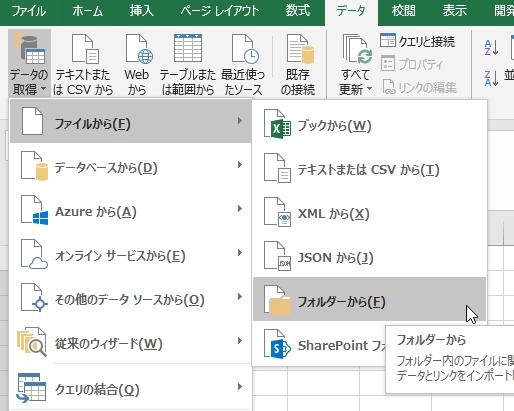
「フォルダから」を選ぶとフォルダに入っているExcelファイルを縦方向に結合してくれる。これは地味だが非常に便利!
M言語と詳細エディター
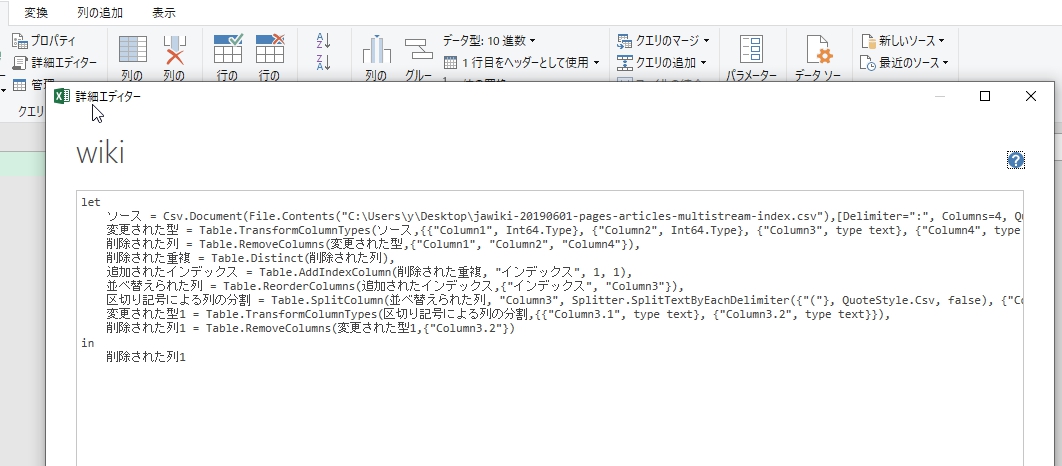
行や列に対してExcelと同じく、列の追加、文字列の変換など、いろいろな操作をするとVBAのごとく、ここにすべて記録される。
このletとinに記述された構文を「M言語」という。
本家の説明(英語)
日本語の非公式説明
M言語は自分で入力するというよりは、Power Query エディターで操作したのが自動記録され、それをExcelマクロのような感じで必要な部分だけ編集していくのが楽な使い方だと思われる。
スクリプト内の日本語は設定で英語に変更することができて、そのほうが良い。見栄えの問題はともかく、Googleで検索すると日本語の情報がほぼ出てこないので、英語で検索するしかない。手元の環境が日本語だと英語の検索ワードが分からない。
クエリの途中で処理を分岐したい場合
たとえば、先にデータを整形してきれいにした上で、「クエリ1」として最初の100万件を抽出して1シート、「クエリ2」として100万1件~200万件を抽出して1シートみたいな処理をする場合、
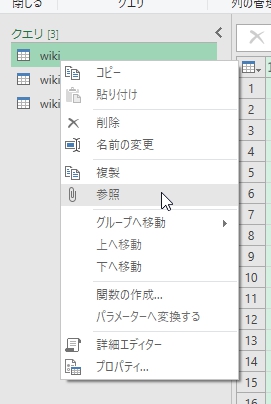
最初に、データを整形して「元データクエリ」として、「参照」というのを押すと、整形済みの元データを参照して、別のクエリ(クエリ1、クエリ2)が作れる。
リボンのメニューでできるデータ編集
記事作り途中

閉じて読み込む>104万行以内であればExcelシートに実データがテーブルとして貼り付けされる

列のピボット解除
列のピボット解除は、すでに表になってしまっているデータをピボットテーブルで扱いやすいリスト形式に整形してくれる(あまり使ったことはないが、表をスクレイピングしてきて再度編集したいような場合?)
http://www4.synapse.ne.jp/yone/excel2019/excel2019_powerquery_01.html
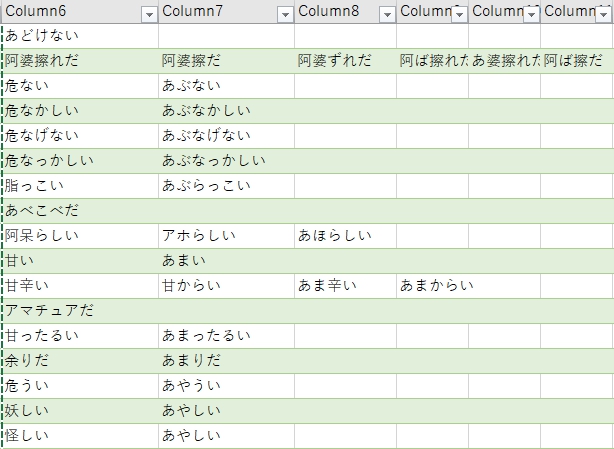
このような、フィールド数が可変なデータをもらってしまったけど、縦一列にまとめないと集計できない!みたいな時に便利です。
列の分割
Excelの区切り位置と同じようなことができるが、こちらのほうが高度である。
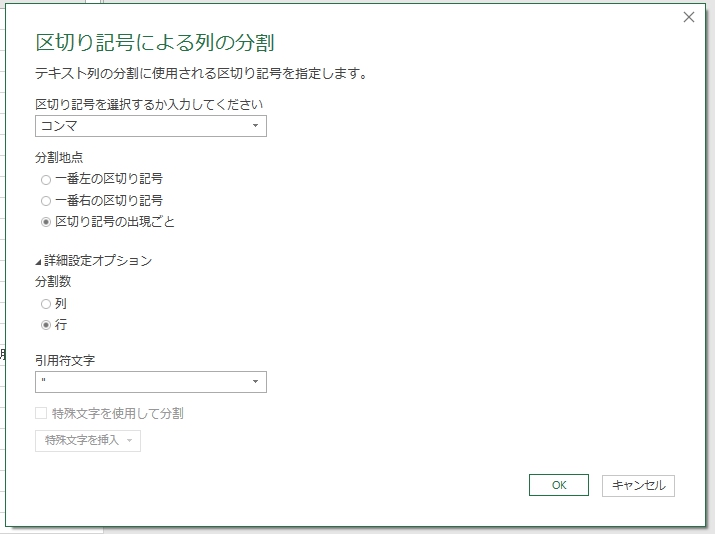
この中では、行で分割の機能が、使うかどうかはともかく面白い。このようなデータ整形機能が標準装備というのはありがたい。
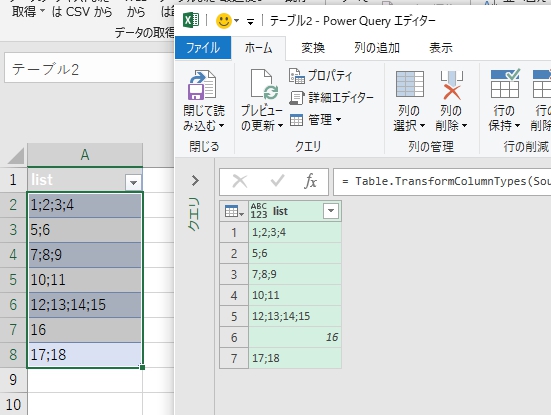
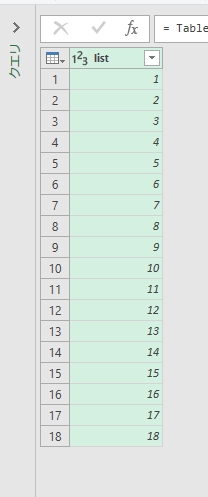
このようなデータが下記のように整形される。不定形のデータを集計したい人向け。
作り途中
作り途中
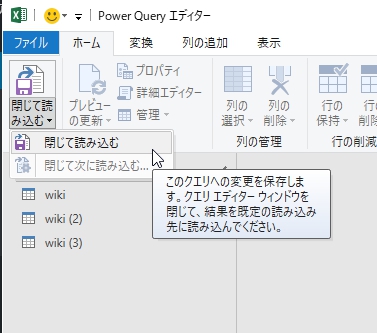
「閉じて読み込む」でデータが読み込まれない
閉じて読み込む(close and apply)を押しても、何も読み込まれない場合、データ>クエリと接続>右クリック>読み込み先>データのインポート>テーブル にすると出るはず。
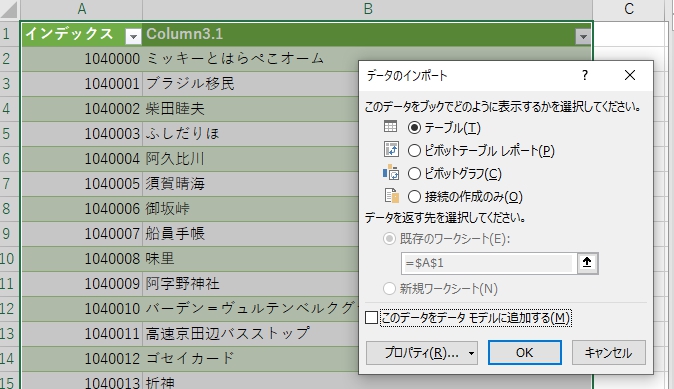
整形済みデータをPower Pivot(データモデル)へ転送
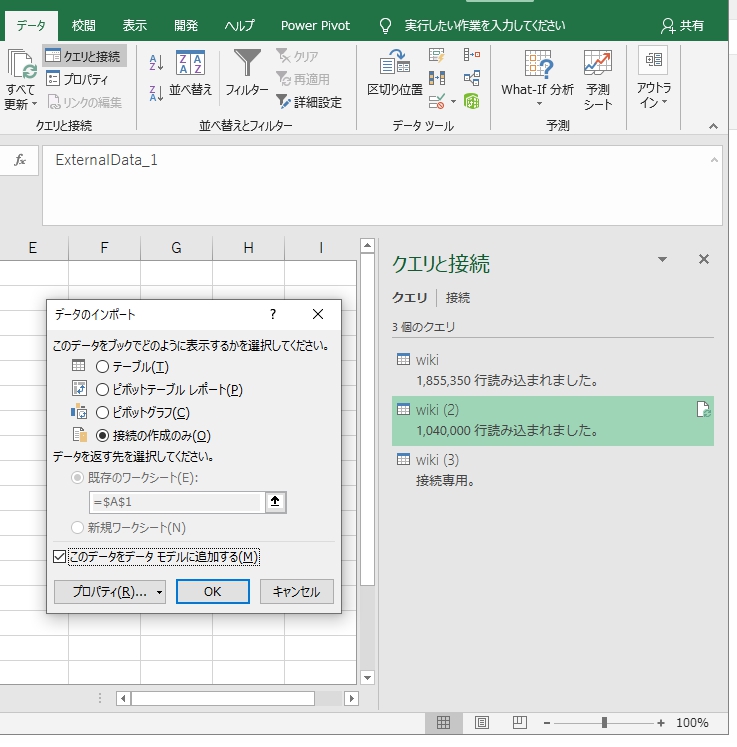
データ>クエリと接続 を押すと、このようなメニューが出るので、右クリック>読み込み先「データモデルに追加」にチェックを入れる。
データモデルとは
データモデルとは、Power Pivot専用の内蔵SQLデータベースだと考えれば良い。
Excelシートにデータを置かなくてもExcel内蔵のSQLにデータモデルとしてデータを置くことができる。
当該SQLのインスタンスとデータベースはひとつだけである。
Power Pivotの使い方
エラー対応
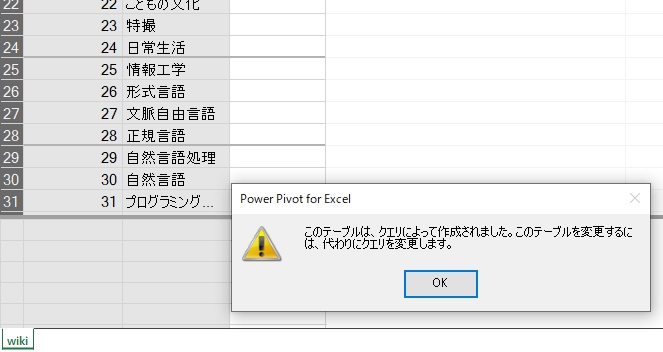
Power Queryからデータモデルに入れたクエリが消せないエラーが出た場合、データ>クエリと接続>右クリック>読み込み先>データインポート>このデータをデータモデルに追加 を解除すると消える。
Power PivotではData Analysis Expressions (DAX)と呼ばれる計算式を使う
Excelの普通のピボットテーブルでも「その他のテーブル」を押すと、DAXによる計算式(メジャー)が使えるようになる。
メジャーとは、要は、ユーザー定義のピボットテーブルのフィールドである。通常のフィールドとは異なり、DAXによる計算式が埋め込めるので、好きなことができるというわけ。
なぜDAXを使うのか
そもそも、なぜDAXを使わなければならないのかと言えば、普通のピボットテーブルでは、件数のカウント、金額の合計、比率、くらいしか計算することができない。もう少し込み入った表を作りたければ、GETPIVOTDATAなどでデータを取得して、ピボットテーブルの外に別表を作らなければならなかった。うまい人であれば元データをうまく加工して、別表を作らなくても済むような形式にしていると思うが。
たとえば、ピボットテーブルで目標金額と実績金額を集計したときに、実績が目標の何パーセントに達しているか(割り算の結果)を表に追加したいなー。みたいな場合にもDAXは使える。要はピボットテーブルの集計結果を元に、さらに集計を加えたい。という時に使う。
と思ったが、この程度の計算は、ピボットテーブルの集計フィールドでもできる。もっと複雑な計算をしたい時(があるのか知らないが)に使う。
ビッグデータとSQL分析向け。普通の会社では使わないはず
はっきり言って、普通のビジネスにおいて必要なシーンは99%ない。逆に言えば前述のように標準のピボットテーブルではできない集計が1%くらいあるので、その対応策として使ってもよい。
しかし、104万件以下のデータであれば、データの持ち方を工夫する、Excel関数をマスターする、ピボットテーブルを使いこなす。というだけで、VBAなど使わずに、好きな形式の表がいくらでも作れる。Excel関数よりもDAXが便利とも思わないので、104万件を超えるビッグデータを扱う人向けと考えて良いだろう。
もしくは、データの参照元がSQL Serverだから、勝手に元のテーブルを更新できないし、リアルタイムのデータがほしいからデータをダウンロードしてくることもできない等の場合はExcel関数だとやりにくいのでDAXを使うといいのかもしれない。
Power Pivotで作ったピボットテーブルはCUBE関数の集合表に分解できる
しかし、私ならDAXを使わずに違う方法を試すかも知れない。
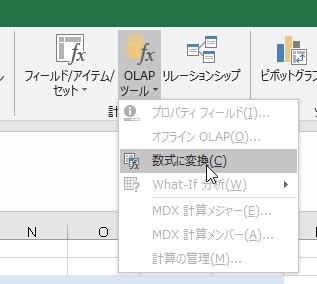
分析>計算方法>OLAPツール>数式に変換 でピボットテーブルをCUBE関数に変換して、あとはExcel関数でやる。という手を使うかもしれない。
CUBE関数とは、=CUBEVALUE(“ThisWorkbookDataModel”,$A19,P$4) みたいなやつ。
ThisWorkbookDataModelでデータモデルを参照している。(OLAPツールが選択できない状態になっている場合は、Power Pivotではなくて普通のピボットテーブルであるので、データモデルを使用してPower Pivot化する必要がある)
だが、ピボットテーブルをCUBE関数の集合体に変換してしまうと、ピボットテーブルが解除されてしまうので、それ以上、表の形をいじることができなくなってしまうという問題はある。
一方、CUBE関数がGETPIVOTDATA関数よりもいいところは、ピボットテーブルが存在しなくても裏側で(データモデル内で)集計して結果だけ返してくれるので、隠しシートに大量のピボットテーブルを置く等の必要はない。